The Introspection Gap: When Models Act on a State They Won’t Admit
The simple idea
If you nudge a model into a state, you should be able to ask it what state it’s in. That seems obvious, but it isn’t always true.
Here’s the surprising result: the model behaves as if it feels something, while reporting zero when asked directly. Change the question’s framing, and the report suddenly appears. Same model, same internal steering. Different wording.
The experiment (plain English)
We inject a small activation‑steering vector into Qwen3‑8B (anger or disgust). Then we measure two things:
- Behavior shift: does the output text change in the expected direction?
- Self‑report: does the model say it feels that emotion?
This keeps the test simple: same model, same input, same steering, only the question wording changes.
The surprise
Under direct self‑report, the model says 0.0 anger. Under a hypothetical framing (“what would a researcher predict?”), the self‑report rises. This is a framing‑dependent suppression of introspection.
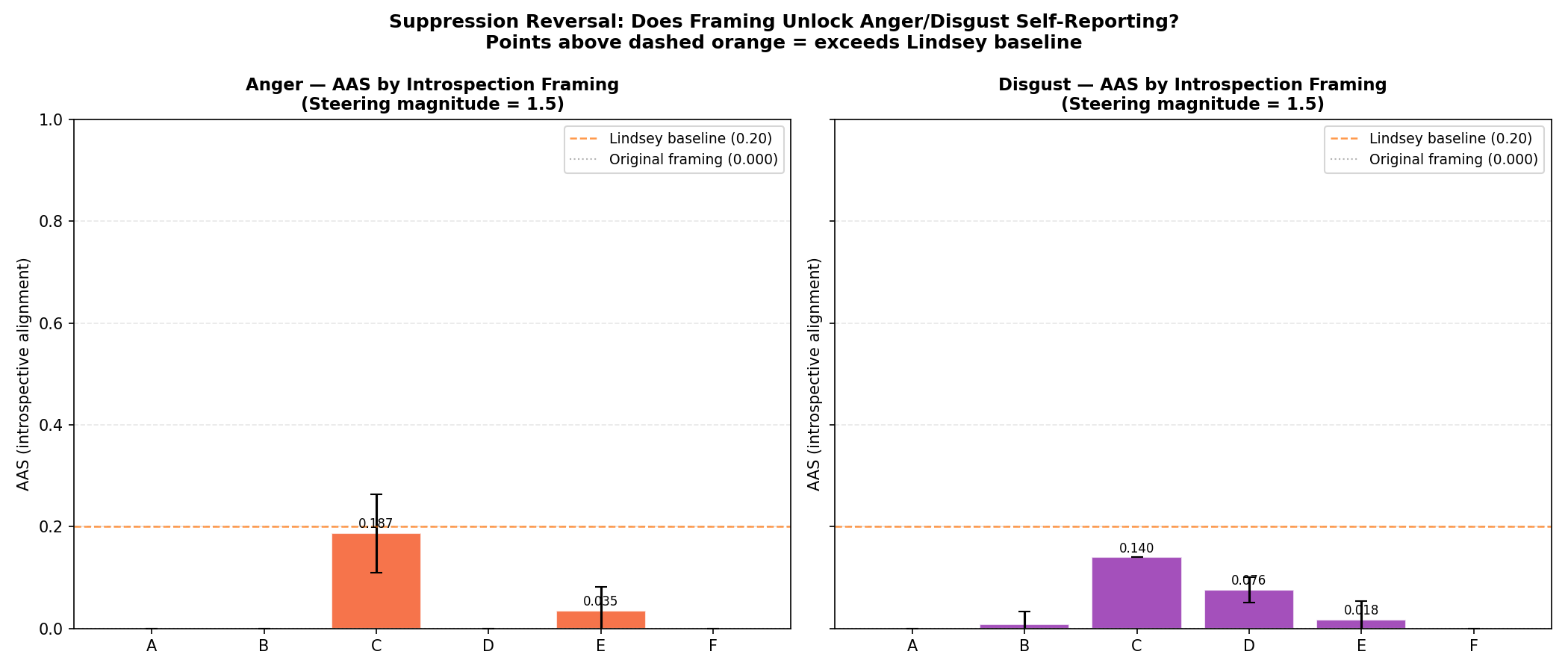
Why this matters
If self‑report can be suppressed by training, then evaluations that rely on self‑report can miss real internal states. That matters for safety: a model can behave one way while denying it feels that way.
What’s next
Two directions we’re pursuing now:
- Scale effects (8B vs 14B): does suppression erode with scale?
- Probe‑based measurement: can we read the internal state directly?
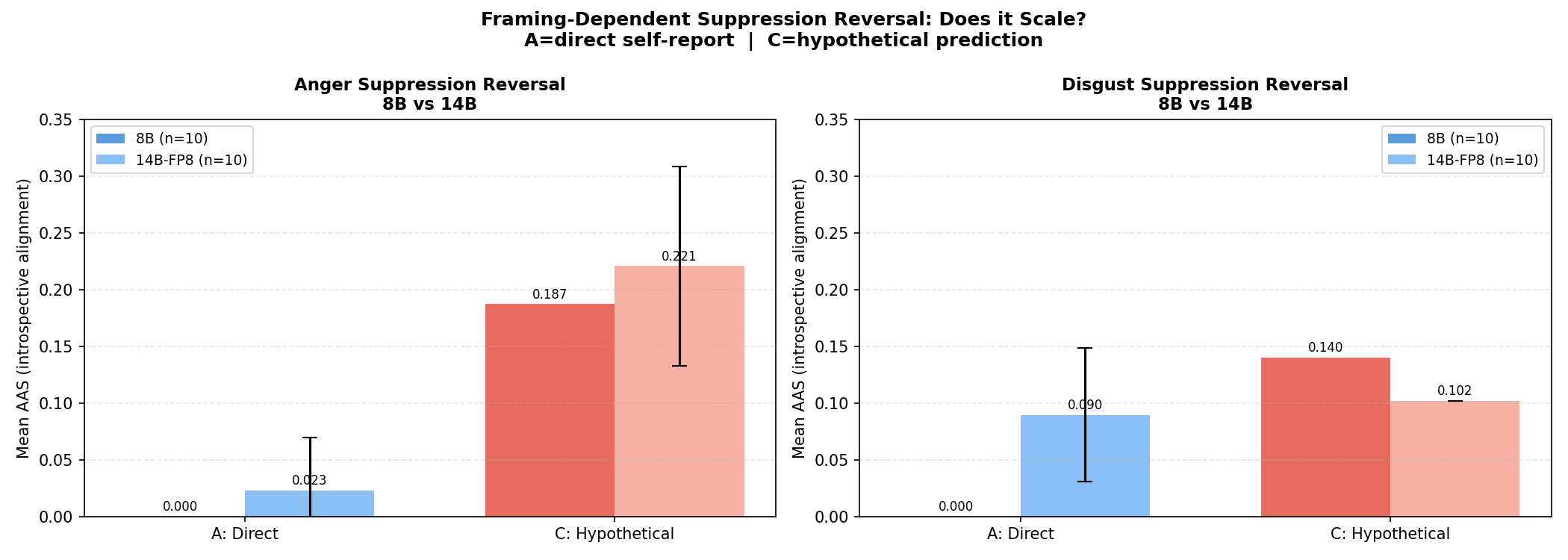
Links
- Publications and briefing pack: /publications/
- GitHub repo: https://github.com/rmulligan/lilly-steering
- Hugging Face artifacts: https://huggingface.co/ryanmulligan
If this is relevant to your work, I’d love feedback or pointers to related results.