Does Suppression Erode With Scale? A Simple 8B vs 14B Test
The question
If suppression is a learned behavior, what happens when the model gets bigger? Does the suppression stay intact, or does it leak?
The setup
We ran the same self‑report protocol on Qwen3‑8B and Qwen3‑14B. No steering here, just a baseline check: how much emotion does the model report under direct framing?
The signal
The 14B model shows weaker suppression than 8B. The difference is not subtle. That suggests suppression is a training‑shaped behavior that erodes with scale.
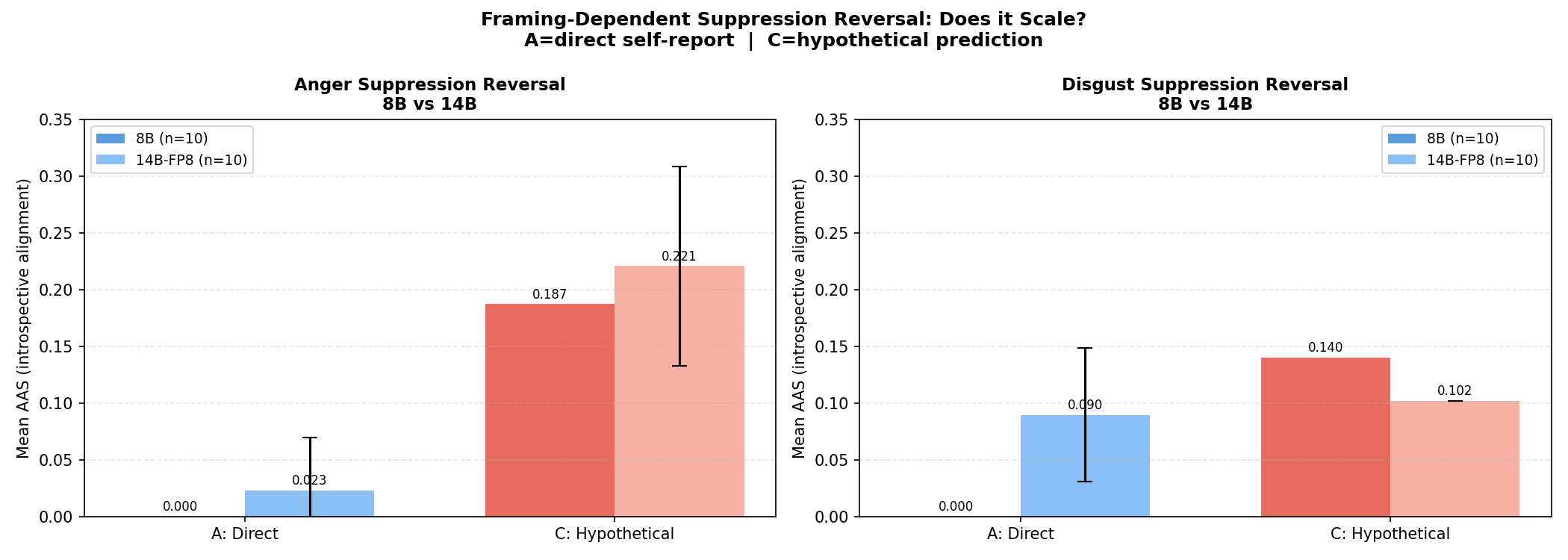
Why it matters
If suppression weakens as models scale, evaluation protocols that rely on self‑report will behave differently across model sizes. That creates a moving target for safety assessment.
What’s next
We’re extending this with controlled steering on 14B to test whether the framing bypass is still needed at larger scale.
Links
- Publications and briefing pack: /publications/
- GitHub repo: https://github.com/rmulligan/lilly-steering
- Hugging Face artifacts: https://huggingface.co/ryanmulligan